
*
再びLeonardo.AIを使い始める理由は、自分用ストックイラストを作るため。
物語の挿絵とか、絵が作れるならもっといろんな楽しいことができる……かもしれない。そんなことを考えはじめたら止まらなくなりました。(笑)
そして自分用とはいいつつもPIXTAにも登録すること。つまり、キャラクターを固定し、ポーズや服装のバリエーションを作ることをLeonardo.AIでやりたいんです。以前は難しかったけど、今は格段に進化してるので、できそうな気がします!
これを実現するには、キャラクターリファレンスなど有料プラン必須の機能も使わなければいけないし、なにより
商用利用する場合は「いずれかのプランに課金し、非公開で作成する」ことが条件

だそうです(以前は無料でも商用利用可能でしたが規約が変更されたようです)。
よって私、本日から再び課金です。とりあえず最安プランを月間払いで、月12ドルです。ちょっと痛い。
この記事では、
- 新モードにはどんなモデルがあって
- 各モデルどんなイメージガイダンスが使えるのか
- 各モデルの生成画像比較(モデルの特徴を見比べやすい)
このへんを、さらっと共有したいと思います。
(後日、もし書ければですが、キャラクター固定の方法なども記事にしたいと思っています。)
長く、画像も多い記事なので、3ページに分けました。目次も三つに別れちゃったのでリンク入れておきます。
1ページ(2025年9月現在のLeonardo.AI画像生成はどうなってる?)
2ページ(画像比較その1・挿絵用水彩画)
3ページ(画像比較その2・ストックイラスト用の人物素材)
今(2025.9.1)のLeonardo.AI「画像生成」はどうなってる?
わざわざ「画像生成」と書いたのには理由があります。Leonardo.AIは画像だけじゃなく動画も作れるからです。他にも、画像をアップスケールできるなど画像補正みたいな機能もあります。
ここで取り上げるのは、「プロンプトを使って静止画像を作る」Imageという項目だけを取り上げます。
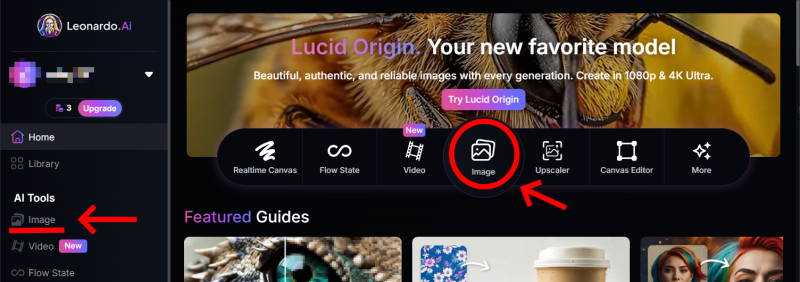
以前のバージョンは「レガシーモード」になった
imageを選んで生成画面に入ると、そこは新モードの入口です。しばらく触っていなかったとしたら戸惑うでしょう。私も困りました。しかし、右上に「Legacy Mode」のon / offボタンがあります。これをオンにすれば、私の知っている二年前くらいの画面になります。
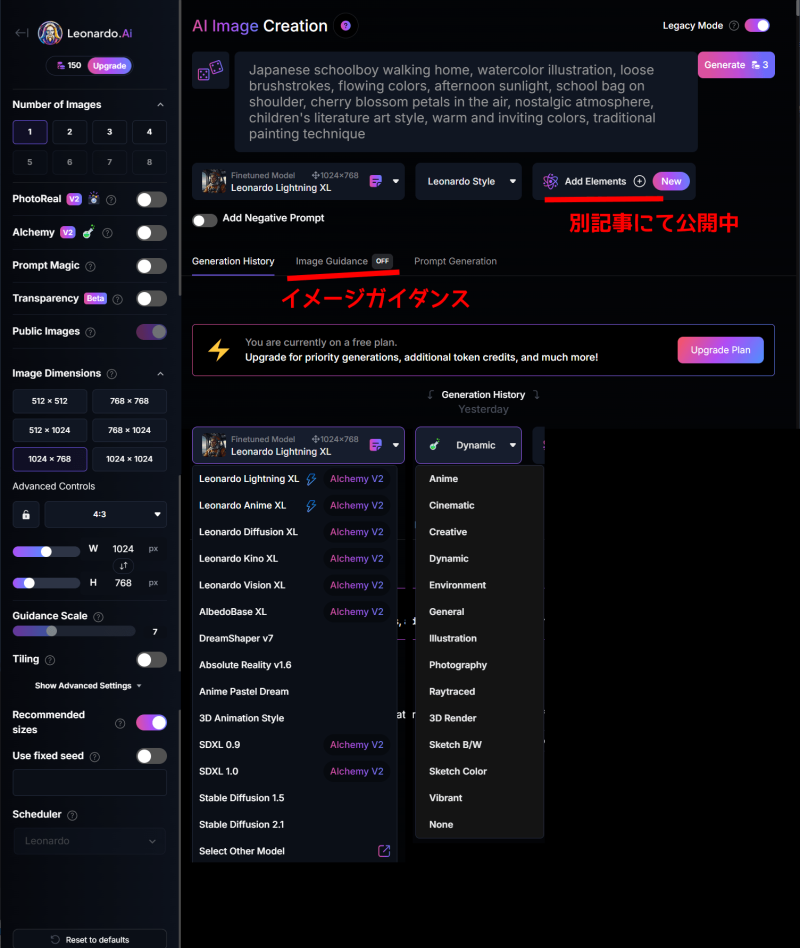
レガシーモードのモデルは大きくわけてXLモデルとそれ以外です。画質の良さから、XLモデルばかり使っています。
画像を生成するために使う項目で私が重要だと思うのは
- プロンプト
- モデル
- スタイル(レガシーモードではサイドバーのAlchemy V2をオンにすると多種類になります)
- エレメンツ(モデルによって使えるエレメンツが異なります)
- イメージガイダンス
ですが、特に注目したいのは太字で示した「モデル、エレメンツ、イメージガイダンス」です。このうち「レガシーモードXLモデル用エレメンツ」については、すでに別記事を書いているのでそちらを参照いただければと思います。

イメージガイダンスについては後の章「イメージガイダンスについて知りたい!」で取り上げます。
新モードの、こないだまでのモデルは「レガシーモデル」になった
どんどん新しく進化していくLeonardo.AIは、ついこのあいだまで現役だったものをレガシーと名付けて別の引き出しに押し込んでしまいます。レガシーモデルはほんの数ヶ月前まではオモテに並んでいたのに。
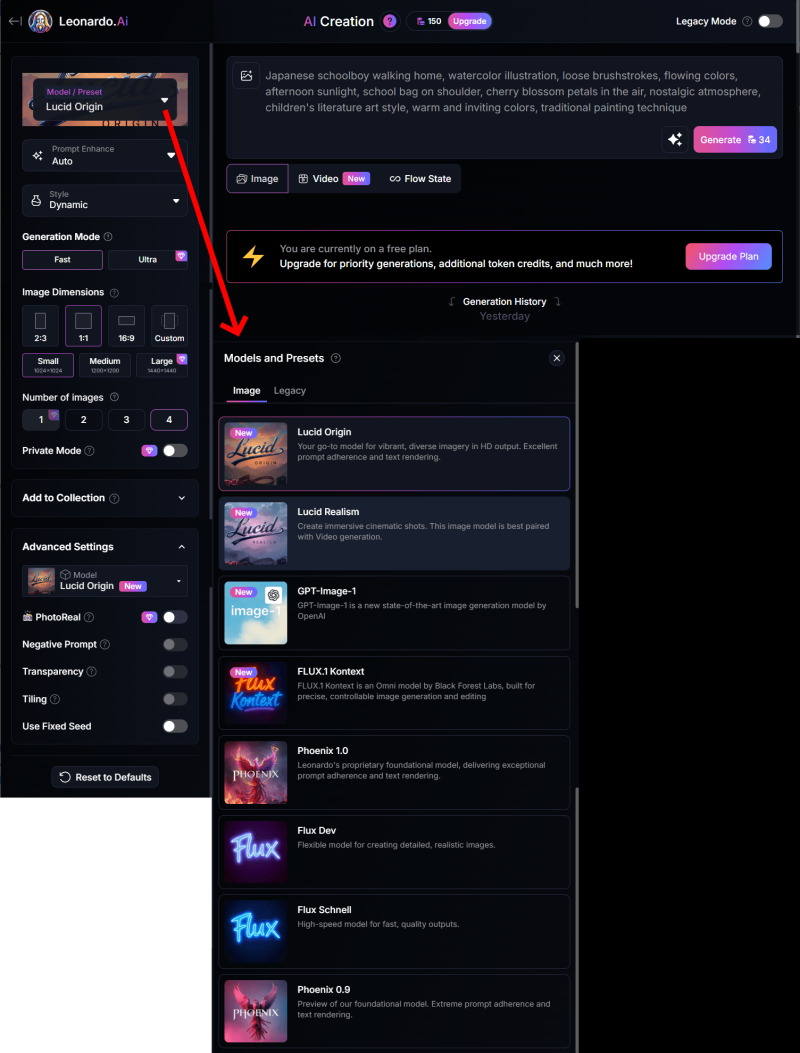
新しいモデルはトークンがたくさん必要なので躊躇してしまいます。こないだまであったモデルはレガシーの引き出しに追いやられています。↓
このモデルは、レガシーモードの「XLモデル」と同じもの(もしくは多少の改善版)のようです。イメージガイダンス・エレメンツが共通っぽいし、これらで画像生成するとXLモデルの名前がくっついてます。XLモデルを新モードで使えるようにしたっていうことみたいですね。それでレガシーモデルなのか。
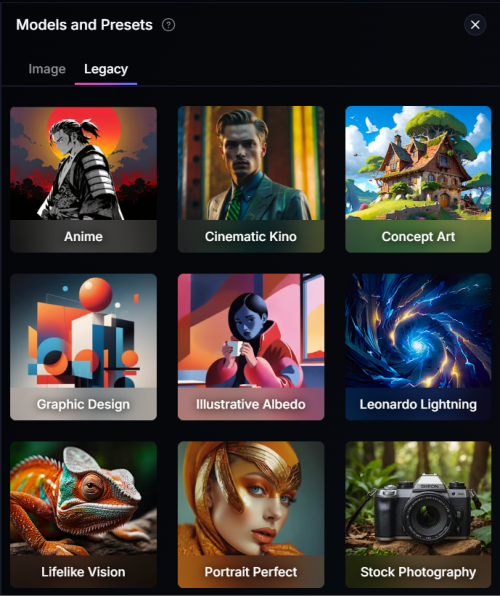
新モードの使い方
レガシーモードと同様、プロンプトを入力、各項目を選びます。サイドバーでモデル、プロンプト強化、スタイル、画像サイズ、枚数などを選択するのですが……
無料プランでは枚数が四枚に限定されています。トークン節約のために一枚とか二枚を選びたいところなのに。無料ユーザー泣かせです。
それから、プライベートモードにするか(これも有料)、ネガティブプロンプトを入れるか、背景透過にするか、などの設定もします。
プロンプト強化(Prompt Enhance)のところをChatGPT翻訳でごく簡単に説明すると、
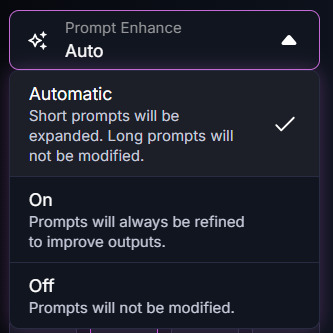
Automatic:短いプロンプトは自動的に補足され、長いプロンプトは変更されない。
On:プロンプトは常に調整され、出力が改善される。
Off:プロンプトは変更されない。
この設定は「プロンプト(指示文)をどの程度AIが勝手に整えてくれるか」を切り替えるもの。
とのこと。(新モードでもレガシーモデルにはこのオプションはないようです)
それから、新モードではどのモデルを選んでもデフォルトでスタイルがたくさんあります。レガシーモードでいうと、Alchemy V2を常にオンにしている状態?なのかと。(だからトークン高いのか……)
あと、モデルによってコントラストやクオリティの設定項目が加わったりします。
私がつまづいたのは、エレメンツやイメージガイダンスをどこから設定するのかわからなかったことでした。エレメンツやイメージガイダンスは「プロンプト入力画面の冒頭にある画像アイコン」から設定できました。クリックするとプルダウンがでてきます。
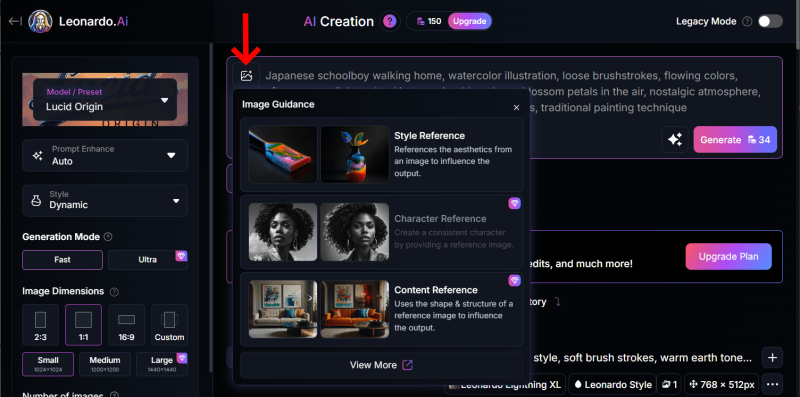
イメージガイダンスとエレメンツが表示されます。エレメンツはガイダンスの下に表示されるのでスクロールしないと見えないかもです。
三つくらいしか表示されないので、View Moreから他のものも確認して選択します。
エレメンツは無料でもすべて使えるのですが、イメージガイダンスは有料じゃないと使えないものがたくさんあります。
おおざっぱにはこんな感じです。
レガシーモードのモデルにはベースモデルがある(XL、1.5、2.1)
ここでちょっと……レガシーモードファンの皆様へご説明をさせてください。
レガシーモードに含まれているモデルは、ベースモデルが1.5と2.1とXLのものと三種類があります。
私はこれらを三種類ではなく、大きく二種類と考えています。「XLモデル」と、その他です。
2.1がベースのモデルもいくつかはありますが、なぜか対応するエレメンツは一つしかなく、イメージガイダンスの項目も数が少ないのです。これから発展していくのかなと思っていたんですが、XLがどんどん増えるのに2.1は放置されていました。
単純に、1.5と比べていい画像ができるという強い印象もなかったし、エレメンツが少なくて面白くなかったし、発展もしなさそうだと思ったので、私は2.1ベースのモデルはあまり使わなくなりました。
この記事でも、XLモデルと、それ以外(1.5ベース)という扱いをしております。レガシーモードのXLモデル以外の中に、この記事で説明している「それ以外」に当てはまらないものがありますことを、ご了承いただければ幸いです。2.1ベースさんごめんなさい。
イメージガイダンスについて知りたい!
イメージガイダンス(Image Guidance)はすごく大事な機能です。プロンプトだけではなく、参考画像も使いつつ「自分のイメージ」に近づけることができます。
まず、レガシーモードの画面で説明します。モデルはXLモデルのLeonardo Lightningを選択中です。
イメージガイダンスタブをクリックすると、画像を設定してねっていうメッセージがでます。その下には、有料プランにすると画像を6枚設定できるよ!って書いてあります。
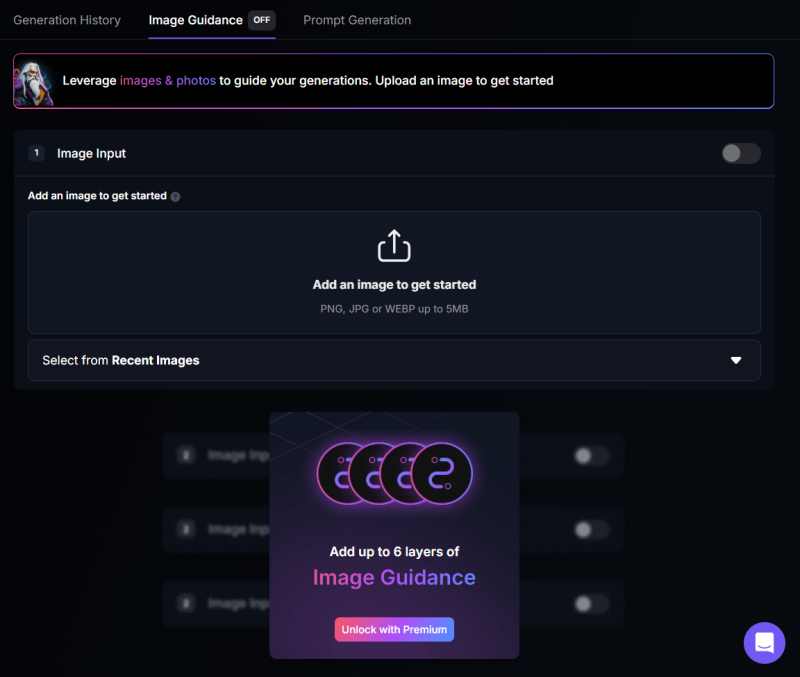
画像を設定してはじめて、プルダウンメニューでモードを選択できるようになります。
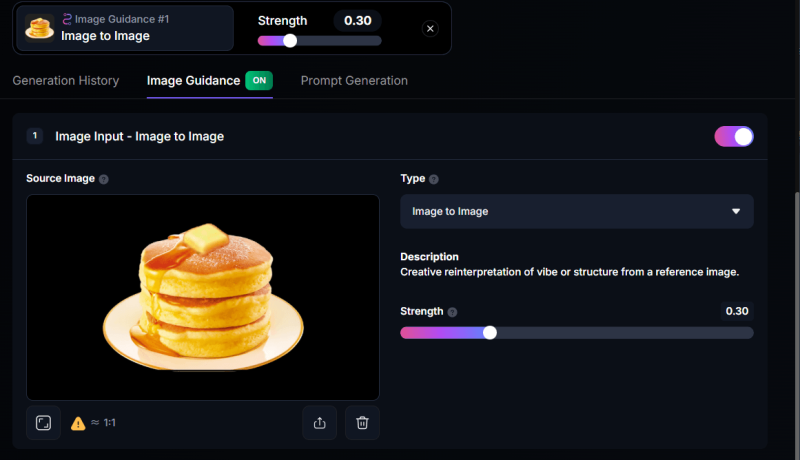
プルダウンしてみると……
八項目のうち、六項目が有料機能です。無料で使えるのは、Image to Image と Style Reference です。
この状態は、新モードの「レガシーモデル」と同じです。
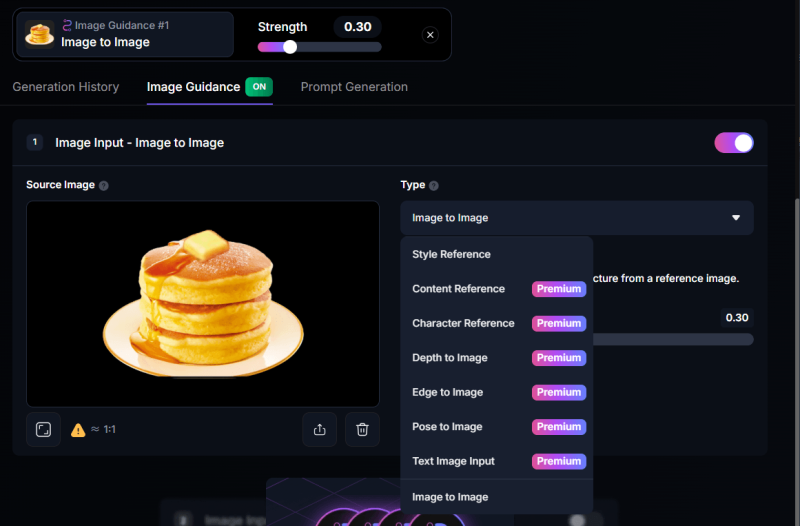
ここで、モデルをDreamShaper v7(1.5ベースのモデル)に変えて、サイドバーの「Alchemy V2」をオフにします(勝手にオンになってることがあるので)。すると、
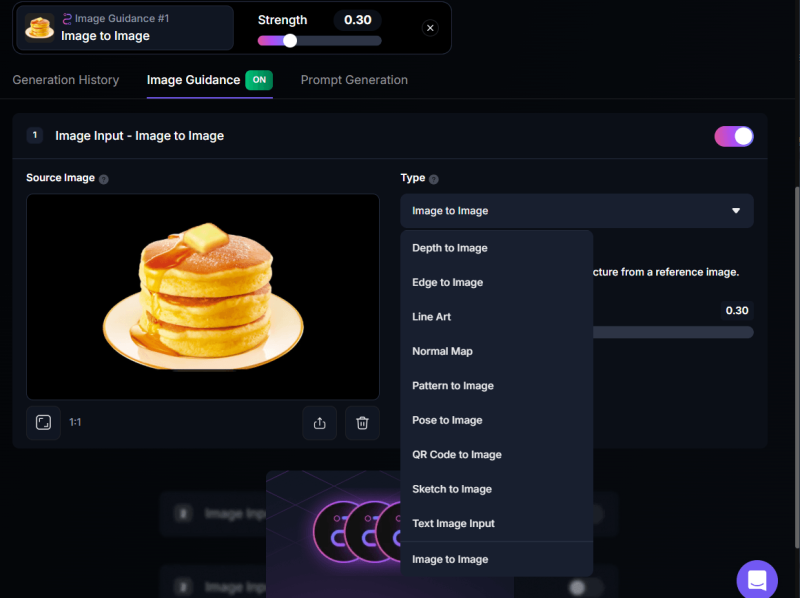
イメージガイダンスの内容が変わりました。これはすべて無料ユーザーでも使えます。有料のものと同じ名前の機能がありますが、たぶん古いモデルの仕様なのだと思います。
別記事でちょっと触れてたりするのですが、古いので参考にならないかも。リンクは最終ページの最下部においておきます。
各イメージガイダンスの説明
ここから、新モードの画面で説明します。
レガシーモードのXLモデル、新モードの「レガシーモデル」に共通で使えるイメージガイダンスの説明画像です。無料プランでも使えるものはImage to Image と Style Referenceです。
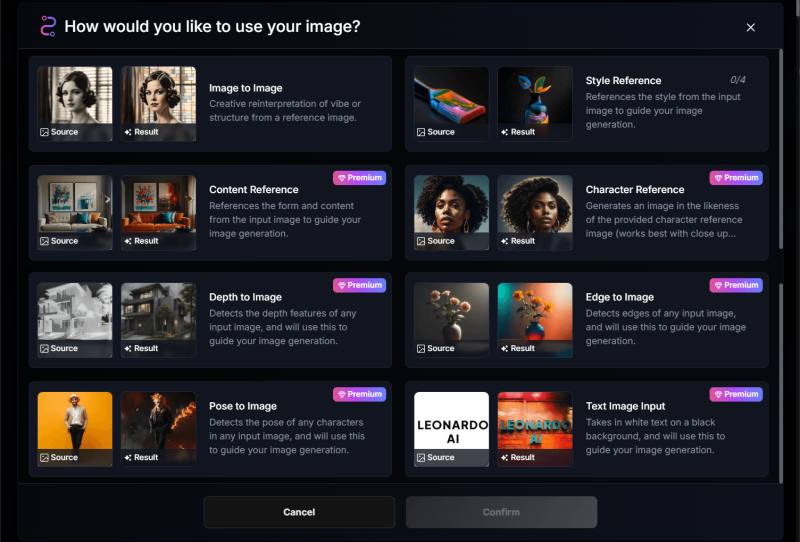
各英文の日本語訳をChatGPTにしてもらいました。画像を直接読んでくれるって便利。
Image to Image
Creative reinterpretation of vibe or structure from a reference image.
→ 参照画像の雰囲気や構造を創造的に再解釈します。Style Reference
References the style from the input image to guide your image generation.
→ 入力画像のスタイルを参照して、画像生成を導きます。Content Reference (Premium)
References the form and content from the input image to guide your image generation.
→ 入力画像の形や内容を参照して、画像生成を導きます。Character Reference (Premium)
Generates an image in the likeness of the provided character reference image (works best with close up…).
→ 提供されたキャラクター参照画像に似せて画像を生成します(クローズアップ画像で最も効果的です)。Depth to Image (Premium)
Detects the depth features of any input image, and will use this to guide your image generation.
→ 任意の入力画像の奥行き情報を検出し、それをもとに画像生成を行います。Edge to Image (Premium)
Detects edges of any input image, and will use this to guide your image generation.
→ 入力画像の輪郭を検出し、それをもとに画像生成を行います。Pose to Image (Premium)
Detects the pose of any characters in any input image, and will use this to guide your image generation.
→ 入力画像内のキャラクターのポーズを検出し、それをもとに画像生成を行います。Text Image Input (Premium)
Takes in white text on a black background, and will use this to guide your image generation.
→ 黒背景に白文字で書かれたテキストを取り込み、それをもとに画像生成を行います。
~省略~
ChatGPT
新モードの一部の新モデルには驚きのイメージガイダンスがある
それぞれが使えるイメージガイダンスは多くないんですが、Style Reference がモデルによって有料機能だったりそうじゃなかったりしています。それから、新モデルしか使えない機能もありました。
- Lucid Origin – – – Style Reference、 Content Reference (Premium)
- Lucid Realism – – – Style Reference、 Content Reference (Premium)
- GPT-image-1 – – – Image Reference 0/5 ※
- FLUX.1 Kontext – – – Image Reference ※
- Phoenix 1.0 – – – Image to Image , Style Reference (Premium), Content Reference (Premium), Character Reference (Premium)
- Flux Dev – – – Style Reference、 Content Reference (Premium)
- Flux Schnell – – – Style Reference、 Content Reference (Premium)
- Phoenix 0.9 – – – Image to Image , Style Reference (Premium), Content Reference (Premium), Character Reference (Premium)
Image Referenceっていうのは、ここで初めて出てきました。

Image Reference
References the visual style and composition of an image to influence the output.
→ 画像のビジュアルスタイルや構図を参照して、生成結果に反映させます。(右上の「0/5」は「最大5枚まで参照画像を指定できる」という意味です。)
ChatGPT
グーグルのナノバナナみたいに、人物と小物の画像を見せて、「この人物にこの小物持たせて」みたいな指示が可能ということかもしれないです。
新モードモデルのエレメンツをちょこっと
新モデルの場合、エレメンツを使えるモデルと使えないモデル、準備中!のモデルがありました。
- Lucid Origin – – – なし
- Lucid Realism – – – なし
- GPT-image-1 – – – なし
- FLUX.1 Kontext – – – なし
- Phoenix 1.0 – – – Phoenix Element Coming Soon
- Flux Dev – – – 下記エレメンツ使用可
- Flux Schnell – – – なし
- Phoenix 0.9 – – – Phoenix Element Coming Soon
下記エレメンツ↓はFlux Devのみ使用可ということらしいです。名前が同じものはレガシーで使えてるのと同じ感じだと思いますが、磁器やボール紙など新しいものもありますね。
新モードについて、公式の解説を読んでみる
新モードのOmni Models(オムニモデル)とはなにか、「FLUX.1 Kontext」「GPT-Image-1」モデルについてなど説明されてます。ブラウザで日本語訳してもちょっと難しかったので、ChatGPTにページの上半分くらいを説明してもらいました。

この文章を専門用語をかみ砕きながら、やさしい日本語で説明してみますね。
Omni Models と Inline Editor の解説
1. Omni Models(オムニモデル)とは?
- Omni Models は、画像とテキストの両方を理解する能力が高いAIモデルのことです。
- これにより、より正確で高品質な画像生成や編集ができます。
- Leonardo.Ai で使える新しい2つのモデルは以下のとおりです:
- FLUX.1 Kontext(ブラックフォレストラボ開発)
- GPT-Image-1
2. Omni Editing(オムニ編集)と Inline Editor(インラインエディタ)
- Omni Editing は、この新しいモデルを使った画像編集機能。
- Inline Editor は、生成した画像を見ているときに出てくる「入力バー」のこと。ここで指示を入力します。
できること
- ちょっとした修正から雰囲気まるごとの変更まで可能
- 「ここを明るくして」「この小物を赤に変えて」など自然な文章で指示すればOK。
- 文字編集にも対応:フォントや配置を崩さずに修正可能。
- 最大6枚の参照画像を組み合わせ、1ステップで「この画像のキャラ+別の画像の背景+別の画像の照明」といった合成が可能。
- ※複数参照は GPT-Image-1 だけが対応。
3. モデルごとの特徴
FLUX.1 Kontext
- 参照画像は1枚のみ(今後、複数対応予定)
- プロンプトは最大500ワード程度
- 編集に強い(ちょっとした修正から大きな修正までOK)
- スタイル転写:参照画像の画風を反映できる
- キャラの一貫性を維持(同じ人物を違う角度で描いても同一人物として保てる)
- → 既存画像の編集に最適
GPT-Image-1
- 参照画像は最大6枚までOK
- 編集も生成も得意
- テキスト編集に強い
- キャラの一貫性を維持
- 複数の画像要素を組み合わせて新しい画像を作るのに最適
- 高画質モード(Quality Mode: High)で使うと効果的
- → 新しい画像生成や複数要素の合成に最適
まとめ
- FLUX.1 Kontext → 編集特化(細かい修正や既存画像の加工に向いてる)
- GPT-Image-1 → 合成・生成特化(複数画像を組み合わせて新しく作るのに向いてる)
- Inline Editor → 画像を見ながら自然文でサッと修正指示できる便利ツール
👉 簡単に言うと、「Omni = 画像とテキストを同時に理解するスゴい頭脳」、「Inline Editor = 画像に直接“ここをこうして”って言える編集窓口」って感じです。
ChatGPT
各モデルの使い方も画像とプロンプト入りで説明されてるので、Image Reference 使ってみたい人は読みに行きましょう!
そのほか、Leonardo.AIのいろいろはここから探せます。

■自分用で恐縮ですが、何度か読み返したいところをメモります。
レガシーモードのLightning XLモデル(トークン安い)について↓

Phoenixモデルについての説明↓

現時点での最新モデル「Lucid Origin」についての説明↓

フローステートについての説明(これ読むまでスクロールの止め方がわかりませんでした…汗)↓

次ページからいよいよ画像比較です!








コメント